Firas Moosvi (Slides adapted from Varada Kolhatkar)
Announcements
Things due this week
Homework 1 (hw1): Due May 16 17:59
You can find the tentative due dates for all deliverables here.
Please monitor Ed Discussion (especially pinned posts and instructor posts) for announcements.
I’ll assume that you’ve watched the pre-lecture videos.
Surveys
Please complete the anonymous restaurant survey on Qualtrics here.
We will try to analyze this data set in the coming weeks.
Gradescope
Make sure you can submit your assignment before the hw1 due date!
It is required for you to work in a GitHub repository, please maintain your GitHub repo up-to-date.
For students on the waitlist: Gradescope Entry code is 9KK5ZR.
Demo: Submit hw1 on Gradescope
We are going to practice submitting HW1 on Gradescope so you all do it at least once!
Checklist for you in the first week
Suggested Workflow for working with Jupyter Notebooks
Create a folder on your computer that will have all the CPSC 330 repos:
~/School/Year3/CPSC330/ <– Consider this your CPSC parent folder
Create subfolders for: hw, class, practice
In the hw folder, you will then clone hw1, hw2, hw3, etc…
In the class folder, you will clone the cpsc330-2025S1 repo which contains all the class jupyter notebooks
Do not make any changes to files in this directory/repo, you will have trouble when you pull stuff during each class.
If you did make changes, you can reset to the last commit and DESTROY any changes you made (be careful with this command) using: git reset --hard
In the practice folder, you can copy any notebooks (.ipynb) and files (like data/*.csv) you want to try running locally and experiment
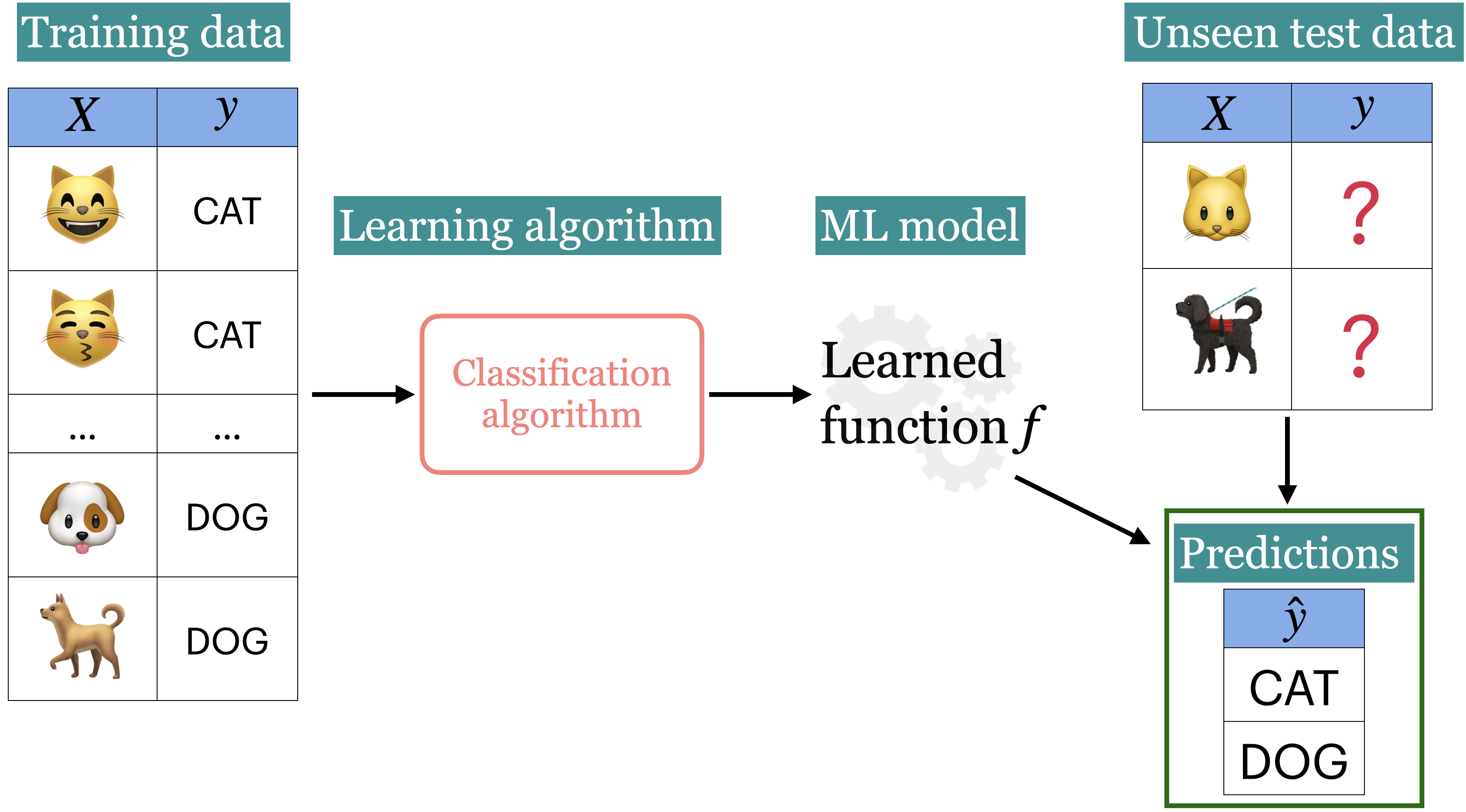
Recap: Machine learning workflow
Supervised machine learning is quite flexible; it can be used on a variety of problems and different kinds of data. Here is a typical workflow of a supervised machine learning systems.
We will build machine learning pipelines in this course, focusing on some of the steps above.
Recap: What is ML?
ML uses data to build models that find patterns, make predictions, or generate content.
It helps computers learn from data to make decisions.
No one model works for every situation.
Recap: Supervised learning
We wish to find a model function \(f\) that relates \(X\) to \(y\).
We use the model function to predict targets of new examples.
In the first part of this course, we’ll focus on supervised machine learning.
Select all of the following statements which are True (iClicker)
Predicting spam is an example of machine learning.
Predicting housing prices is not an example of machine learning.
For problems such as spelling correction, translation, face recognition, spam identification, if you are a domain expert, it’s usually faster and scalable to come up with a robust set of rules manually rather than building a machine learning model.
If you are asked to write a program to find all prime numbers up to a limit, it is better to implement one of the algorithms for doing so rather than using machine learning.
Google News is likely be using machine learning to organize news.
Imagine you’re in the fortunate situation where, after graduating, you have a few job offers and need to decide which one to choose. You want to pick the job that will likely make you the happiest. To help with your decision, you collect data from like-minded people. Here are the first few rows of this toy dataset.
Can you think of other relevant features for this problem?
What is an example?
Classification vs. Regression
Is this a classification problem or a regression problem?
supportive_colleagues
salary
free_coffee
boss_vegan
happy?
0
0
70000
0
1
Unhappy
1
1
60000
0
0
Unhappy
2
1
80000
1
0
Happy
3
1
110000
0
1
Happy
4
1
120000
1
0
Happy
5
1
150000
1
1
Happy
6
0
150000
1
0
Unhappy
Prediction vs. Inference
Inference is using the model to understand the relationship between the features and the target
Why certain factors influence happiness?
Prediction is using the model to predict the target value for new examples based on learned patterns.
Of course these goals are related, and in many situations we need both.
Training
In supervised ML, the goal is to learn a function that maps input features (\(X\)) to a target (\(y\)).
The relationship between \(X\) and \(y\) is often complex, making it difficult to define mathematically.
We use algorithms to approximate this complex relationship between \(X\) and \(y\).
Training is the process of applying an algorithm to learn the best function (or model) that maps \(X\) to \(y\).
In this course, I’ll help you develop an intuition for how these models work and demonstrate how to use them in a machine learning pipeline.
Separating \(X\) and \(y\)
In order to train a model we need to separate \(X\) and \(y\) from the dataframe.
X = toy_happiness_df.drop(columns=["happy?"]) # Extract the feature set by removing the target column "happy?"y = toy_happiness_df["happy?"] # Extract the target variable "happy?"
Baseline
Let’s try a simplest algorithm of predicting the most popular target!
from sklearn.dummy import DummyClassifier# Initialize the DummyClassifier to always predict the most frequent classmodel = DummyClassifier(strategy="most_frequent")# Train the model on the feature set X and target variable ymodel.fit(X, y)# Add the predicted values as a new column in the dataframetoy_happiness_df['dummy_predictions'] = model.predict(X)# Show the dataframetoy_happiness_df
supportive_colleagues
salary
free_coffee
boss_vegan
happy?
dummy_predictions
0
0
70000
0
1
Unhappy
Happy
1
1
60000
0
0
Unhappy
Happy
2
1
80000
1
0
Happy
Happy
3
1
110000
0
1
Happy
Happy
4
1
120000
1
0
Happy
Happy
5
1
150000
1
1
Happy
Happy
6
0
150000
1
0
Unhappy
Happy
Break
Let’s take a break!
Decision trees
Activity: 20 Questions
Let’s play 20 questions! You can ask me up to 20 Yes/No questions to figure out the answer.
I’m thinking of a person - who is it ?
Intuition
Decision trees find the “best” way to split data to make predictions.
Each split is based on a question, like ‘Are the colleagues supportive?’
The goal is to group data by similar outcomes at each step.
Now, let’s see a decision tree using sklearn.
Decision tree with sklearn
Let’s train a simple decision tree on our toy dataset.
from sklearn.tree import DecisionTreeClassifier # import the classifierfrom sklearn.tree import plot_treemodel = DecisionTreeClassifier(max_depth=2, random_state=1) # Create a class objectmodel.fit(X, y)plot_tree(model, filled=True, feature_names = X.columns, class_names=["Happy", "Unhappy"], impurity =False, fontsize=12);
Prediction
Given a new example, how does a decision tree predict the class of this example?
What would be the prediction for the example below using the tree above?
Select all of the following statements which are TRUE.
Change in features (i.e., binarizing features above) would change DummyClassifier predictions.
predict takes only X as argument whereas fit and score take both X and y as arguments.
For the decision tree algorithm to work, the feature values must be binary.
The prediction in a decision tree works by routing the example from the root to the leaf.
Break
Let’s take a break!
Group Work: Class Demo & Live Coding
In some of the classes, we will do a bit of live coding to get your used to practical machine learning. You are highly encouraged to follow along - we won’t usually finish everything in the demo, but it should be a significant portion that you can finish off after class.
For this demo, each student should click this link to create a new repo in their accounts, then clone that repo locally to follow along with the demo from today.