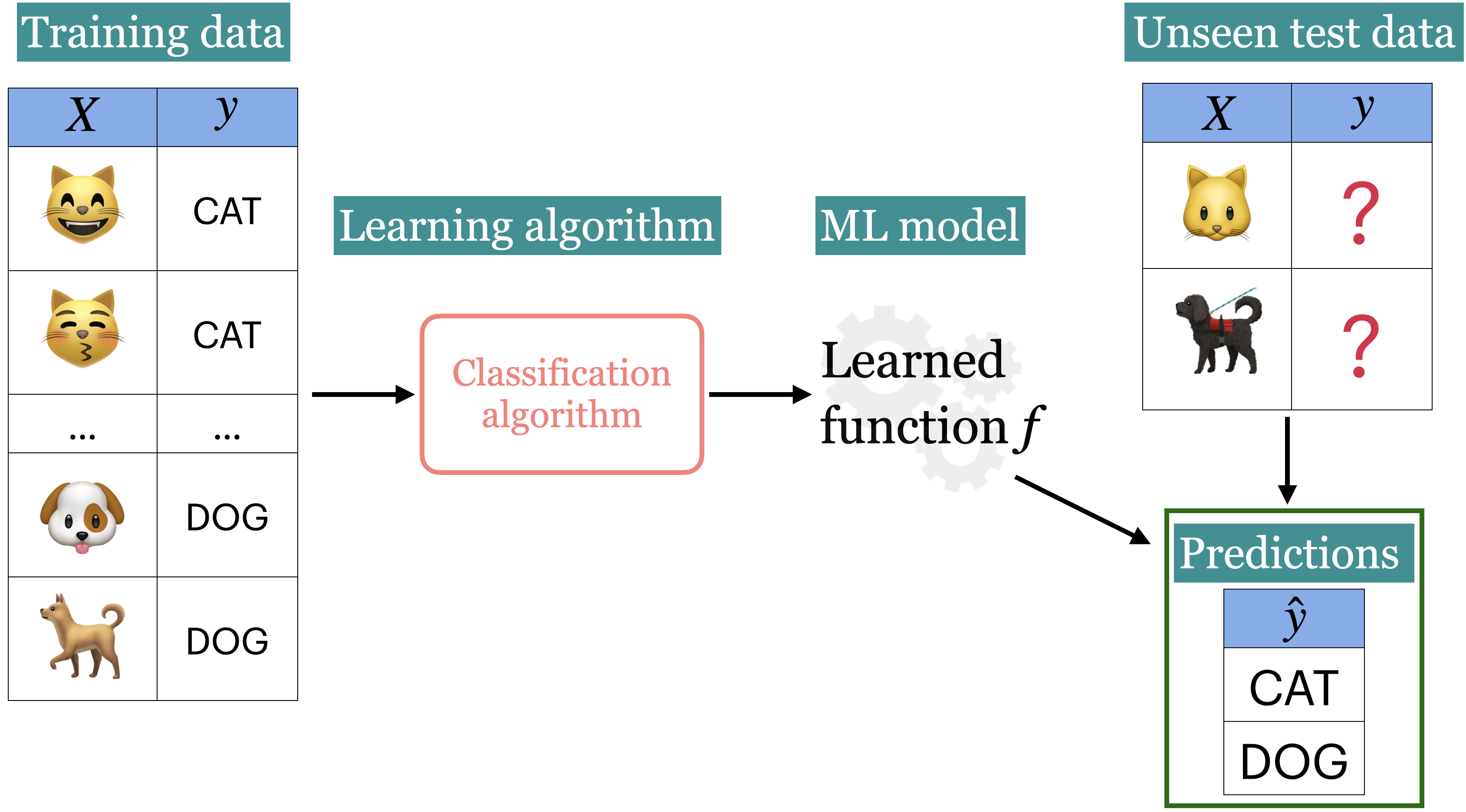
Imagine you’re in the fortunate situation where, after graduating, you have a few job offers and need to decide which one to choose. You want to pick the job that will likely make you the happiest. To help with your decision, you collect data from like-minded people.
Can you think of relevant features for this problem?
Is this a classification problem or a regression problem?
supportive_colleagues
salary
free_coffee
boss_vegan
happy?
0
0
70000
0
1
Unhappy
1
1
60000
0
0
Unhappy
2
1
80000
1
0
Happy
3
1
110000
0
1
Happy
4
1
120000
1
0
Happy
5
1
150000
1
1
Happy
6
0
150000
1
0
Unhappy
(Optional) Inference vs. Prediction
Inference asks: Why does something happen?
Goal: understand and quantify the relationship between variables
Often involves estimating model parameters and testing hypotheses
Example: Which factors influence happiness, and by how much?
Prediction asks: What will happen?
Goal: accurately predict the target without needing to fully explain the relationships
Example: Will you be happy in a particular job?
Of course these goals are related, and in many situations we need both.
Training
In supervised ML, the goal is to learn a function that maps input features (\(X\)) to a target (\(y\)).
The relationship between \(X\) and \(y\) is often complex, making it difficult to define mathematically.
We use algorithms to approximate this complex relationship between \(X\) and \(y\).
Training is the process of applying an algorithm to learn the best function (or model) that maps \(X\) to \(y\).
In this course, I’ll help you develop an intuition for how these models work and demonstrate how to use them in a machine learning pipeline.
Error and accuracy
Machine learning models are not perfect—they will make mistakes.
To judge whether a model is useful, we need to track its performance.
For classification problems, the most common (and default in sklearn) metric is accuracy:
\[
\text{Accuracy} = \frac{\text{Number of correct predictions}}{\text{Total number of examples}}
\]
Separating \(X\) and \(y\)
In order to train a model we need to separate \(X\) and \(y\) from the dataframe.
X = toy_happiness_df.drop(columns=["happy?"]) # Extract the feature set by removing the target column "happy?"y = toy_happiness_df["happy?"] # Extract the target variable "happy?"
Baseline
Let’s try a simplest algorithm of predicting the most popular target!
from sklearn.dummy import DummyClassifiermodel = DummyClassifier(strategy="most_frequent") # Initialize the DummyClassifier to always predict the most frequent classmodel.fit(X, y) # Train the model on the feature set X and target variable ytoy_happiness_df['dummy_predictions'] = model.predict(X) # Add the predicted values as a new column in the dataframetoy_happiness_df
supportive_colleagues
salary
free_coffee
boss_vegan
happy?
dummy_predictions
0
0
70000
0
1
Unhappy
Happy
1
1
60000
0
0
Unhappy
Happy
2
1
80000
1
0
Happy
Happy
3
1
110000
0
1
Happy
Happy
4
1
120000
1
0
Happy
Happy
5
1
150000
1
1
Happy
Happy
6
0
150000
1
0
Unhappy
Happy
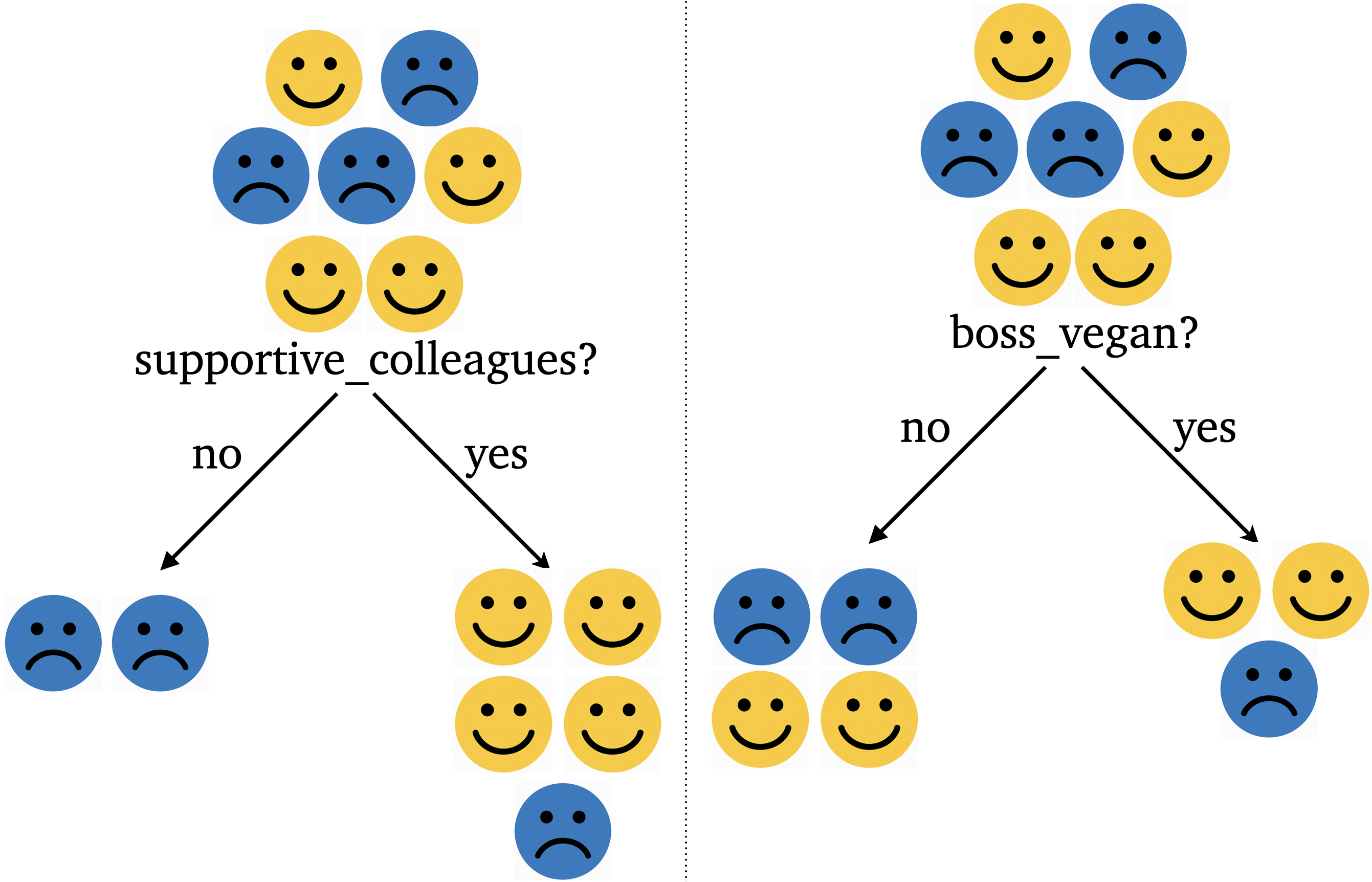
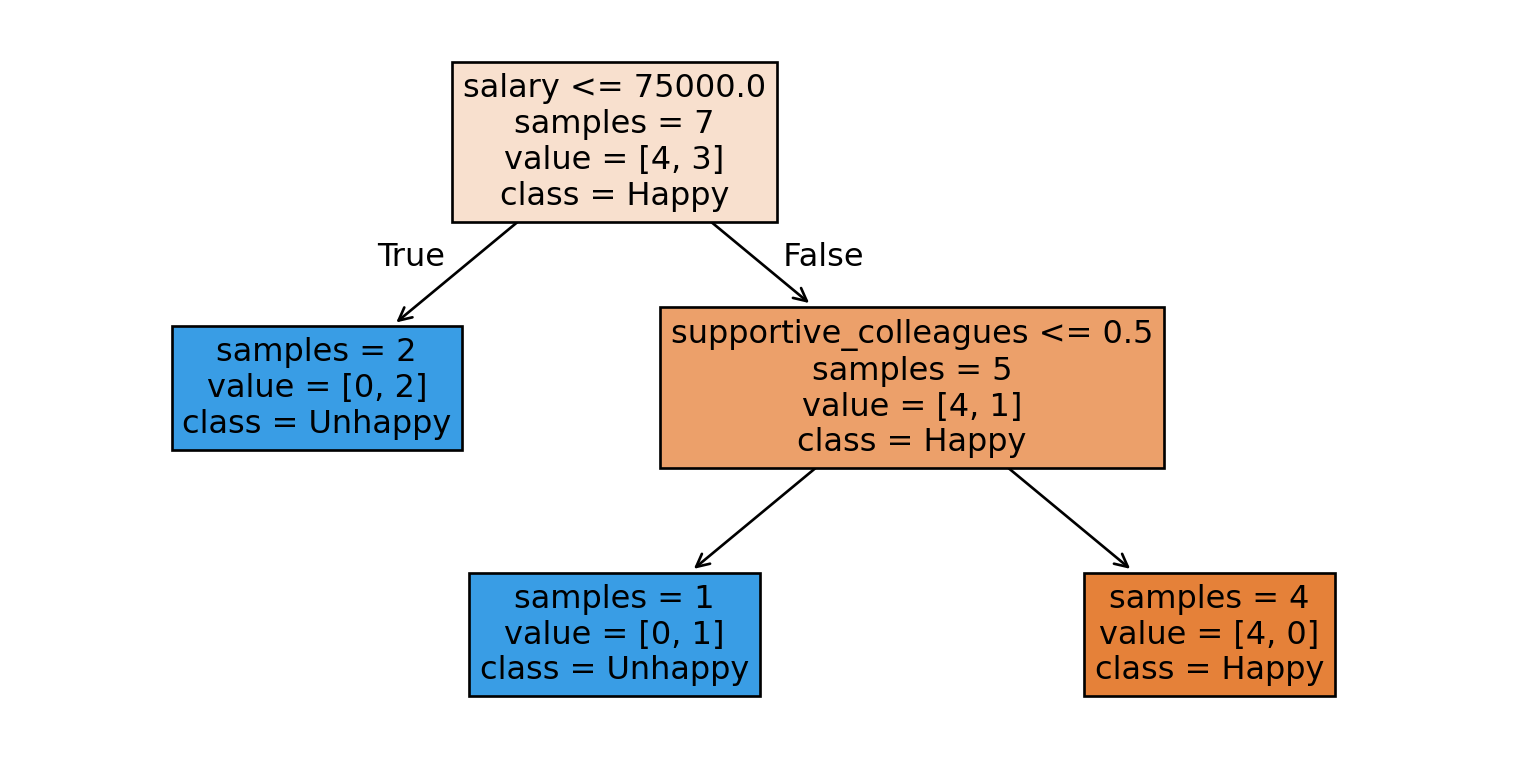
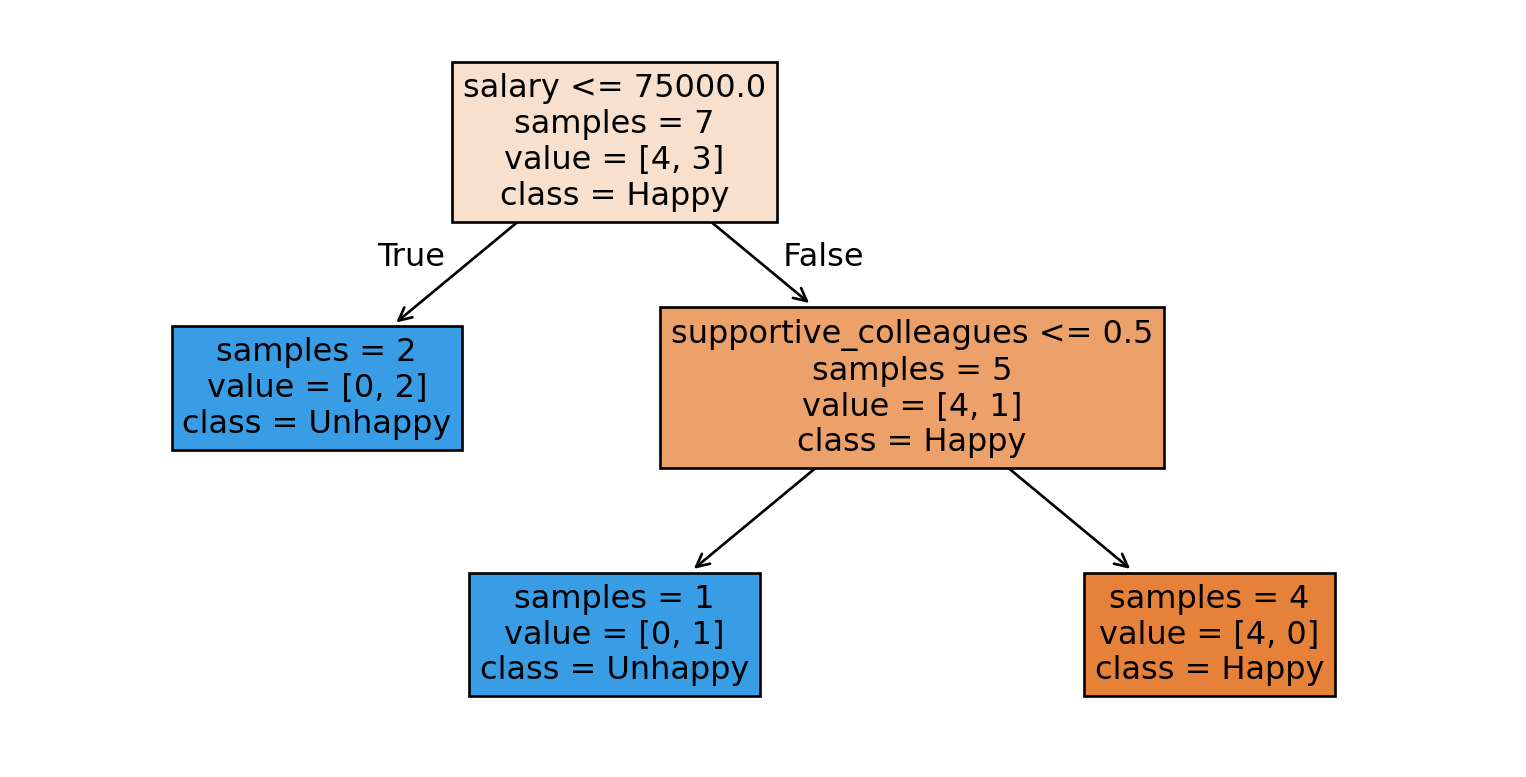
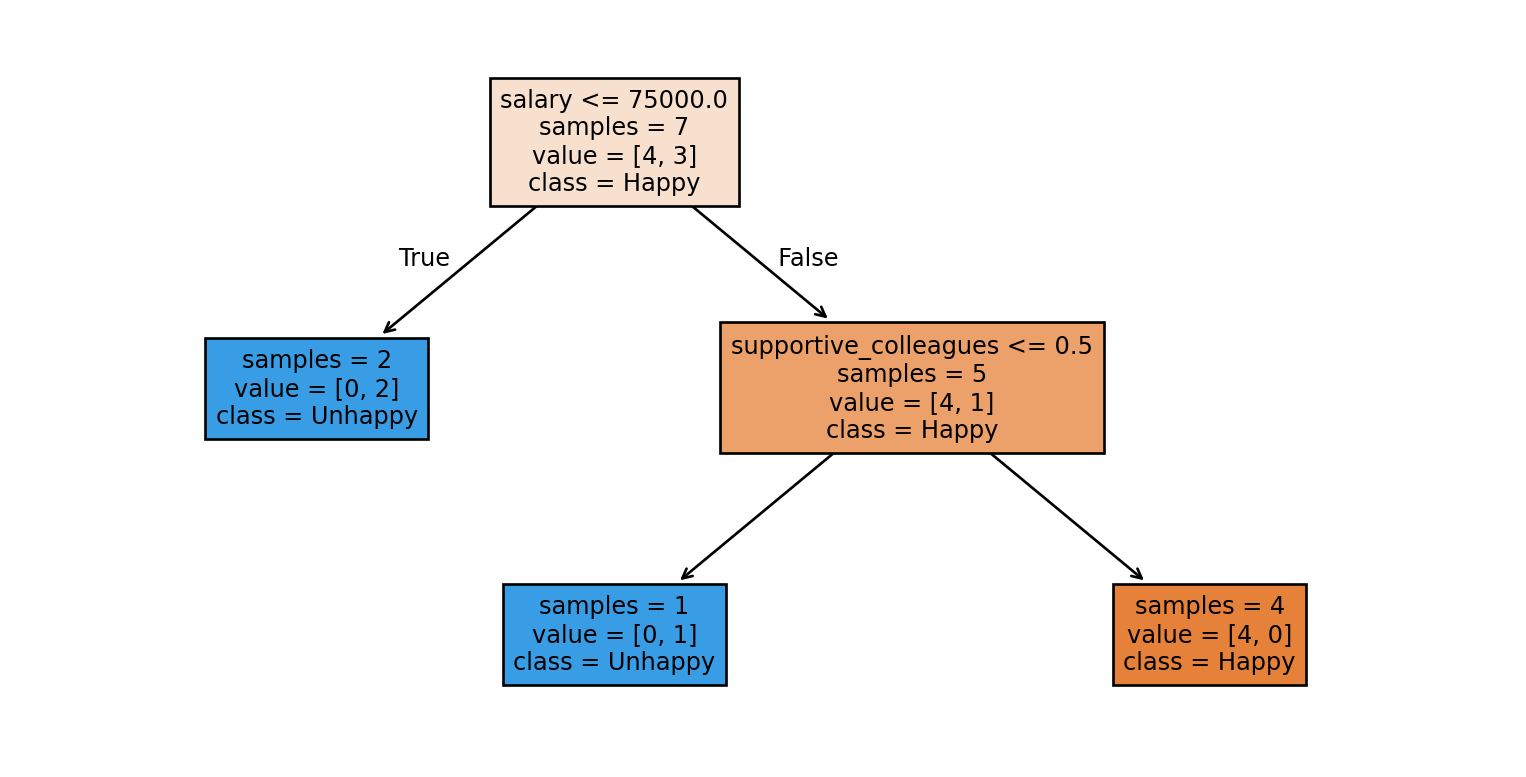
Decision trees intuition
One intuitive way to build a model is by asking a series of yes/no questions, forming a tree.
Which question would help you best separate the happy and unhappy examples?
The questions (features and thresholds) used to split the data at each node.
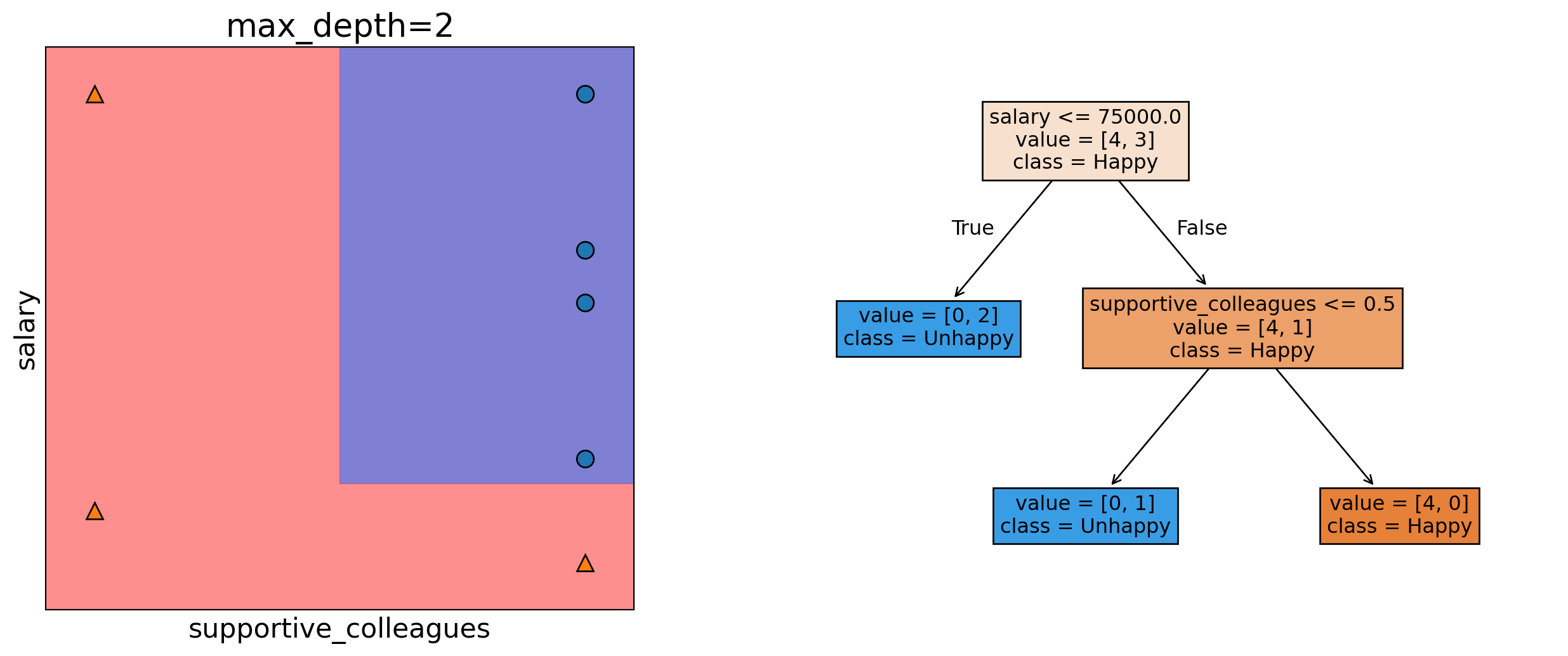
Example: salary <= 75000 at the root node
Hyperparameters
Settings that control tree growth, like max_depth, which limits how deep the tree can go.
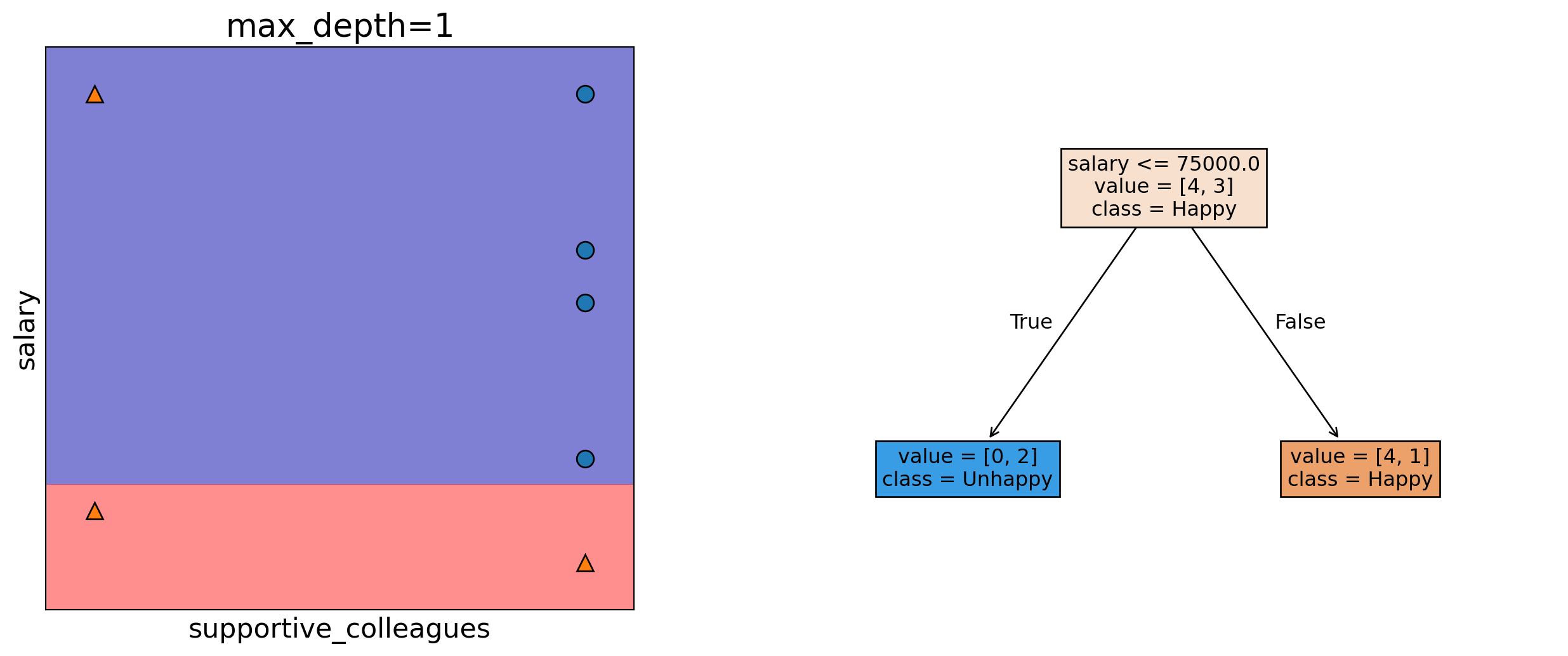
Decision boundary
A decision boundary is the line, curve, or surface that separates classes.
Points on one side \(\rightarrow\) Model predicts Class Happy
Points on the other side \(\rightarrow\) Model predicts Class Unhappy
Decision boundary with max_depth=1
Decision boundary with max_depth=2
Clicker 2.4: Baselines and Decision trees
iParticipate using Agora (code: canvas)
Select all of the following statements which are TRUE.
Change in features (i.e., binarizing features above) would change DummyClassifier predictions.
predict takes only X as argument whereas fit and score take both X and y as arguments.
For the decision tree algorithm to work, the feature values must be binary.
The prediction in a decision tree works by routing the example from the root to the leaf.
Summary
Terminology
sklearn basic steps
Decision tree intuition
Break
Let’s take a break!
Group Work: Class Demo & Live Coding
In some of the classes, we will do a bit of live coding to get your used to practical machine learning. You are highly encouraged to follow along - we won’t usually finish everything in the demo, but it should be a significant portion that you can finish off after class.
For this demo, each student should click this link to create a new repo in their accounts, then clone that repo locally to follow along with the demo from today.