Lecture 17: Natural Language Processing
Which metric in what context?
Given a query vector “Query” in the picture below and the three item vectors, determine the ranking of the items for the three similarity measures below:
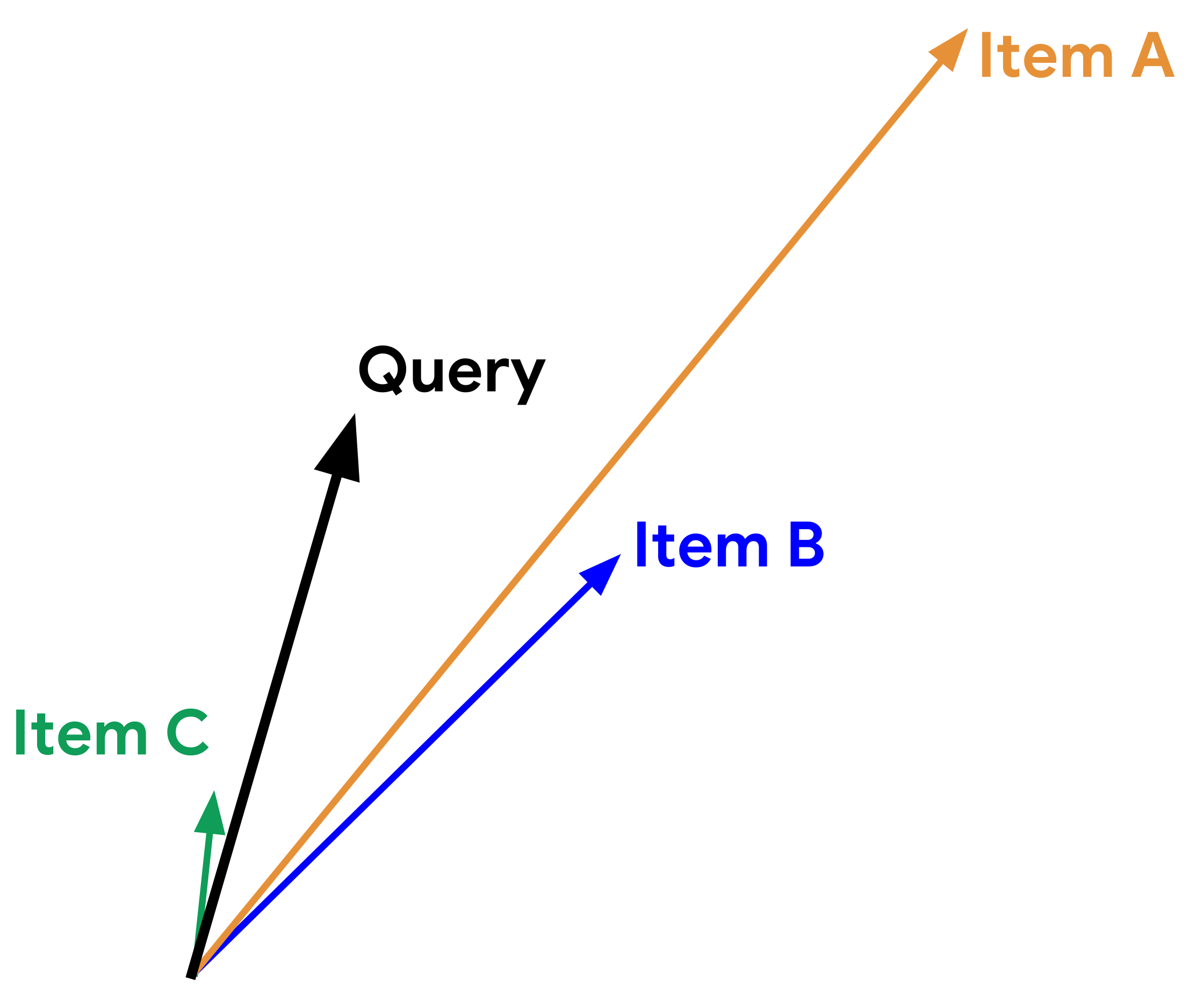
- Example: Similarity based on Euclidean distance: item B > item C > item A
- Similarity based on dot product: ?
- Cosine similarity: ?
Adapted from here.
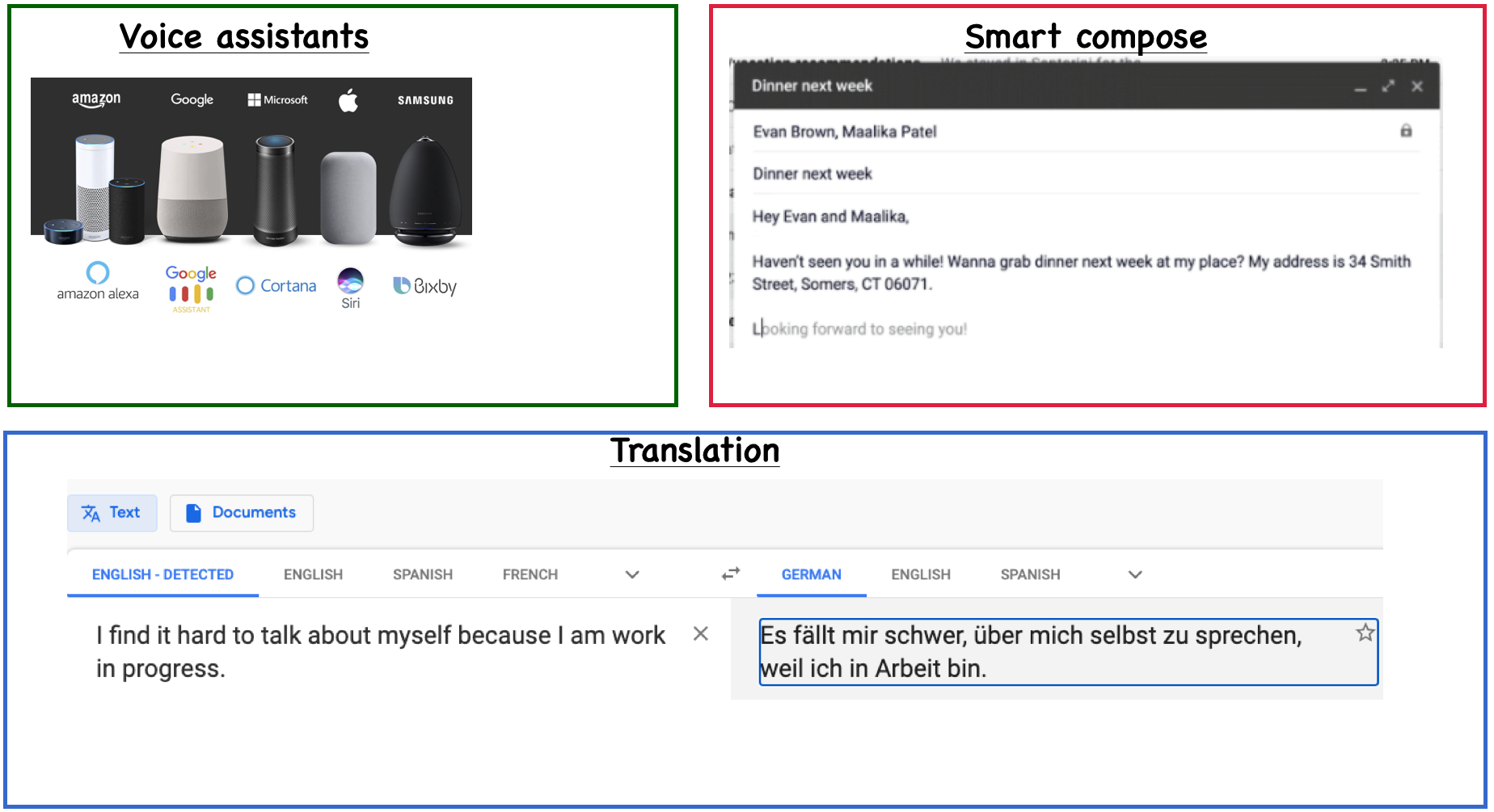
Examples of NLP applications
Activity: Context and word meaning
Pair up with the person next to you and try to guess the meanings of two made-up words: flibbertigibbet and groak.

Attribution: Thanks to ChatGPT 4o on Wed Nov. 6, 2024!